
ワイルドカードは、クエリの中に含めることができる特殊な文字です。ワイルドカードを使用することで、特定のタームのバリエーションを検索できます。ワイルドカードを使えば、短い文字列で、スペルが似た語を効率よく検索して、データベース内でマッチするタームを多数見つけることができます。MarkLogic の検索では、次の2つのワイルドカード文字がサポートされています。
* | 空白を除く、0個以上の文字にマッチします。例えば、car* は、car、care、caring(および car で始まる他のすべてのターム)にマッチします。 |
|---|---|
? | 空白を除く、1つの文字のみにマッチします。例えば、car? は、care および cart にマッチしますが、car や caring にはマッチしません。 |
ワイルドカードは、検索タームの先頭、途中、または末尾で使用でき、それらを組み合わせることもできます(例:*e*?her?*)。
ワイルドカード検索に似た機能として、ステミング(語幹処理)があります。これは、MarkLogic でクエリを処理するときに、文法的に似た語を自動的に考慮する機能です。ステミングがオンのとき、MarkLogic で swim を検索すると、swam および swimming も考慮されます。詳細については、『Search Developer’s Guide』の「ステミング検索の概要と使い方」のセクションを参照してください。
MarkLogic では、次の3タイプのインデックスを使用したワイルドカード検索がサポートされています。
- three-character indexes(3文字以上の連続する非ワイルドカード文字を含む検索パターン)
- trailing wildcard indexes(末尾にワイルドカードがある検索パターン)
- レキシコン(語彙集)
これらのインデックスがいつどのように使用されるかは、検索するワイルドカードのパターンによって変わります。
Three-Character Indexes
インデックスは、MarkLogic の通常検索において重要であるだけでなく、ワイルドカードの処理においても重要な役割を果たします。インデックスは、データベースドキュメント内の文字シーケンスを取得して、それらをドキュメントIDにマッピングしたものです。MarkLogic による一般的な検索では、クエリを分析して複雑なクエリを構成要素に分解してから、インデックスを参照してマッチする結果のリストを返しています。デフォルトでは、データベース内のすべての語と、要素名および属性名(XMLドキュメントの場合)やプロパティ名(JSON ドキュメントの場合)などの構造情報に対してインデックスが付けられます。ワイルドカードなどの特定の機能をサポートするために、追加のシーケンスに対して MarkLogic にインデックスを付けさせることができます。
データベースで three-character index をオンにすると、MarkLogic によってすべての一意の3文字シーケンスが、対応するドキュメントにマッピングされます。例えば、cater というタームがドキュメント内にある場合は、cat、ate、および ter のエントリがインデックスに追加されます。また、各シーケンスが語の最初にあったのか最後にあったのかを示すコンテキスト情報も含められます。three-character index は、*ate、ate*、*ate* などの、3つの文字と * を含んだワイルドカード検索を処理するのに最適です。MarkLogic は、結果に必要なすべてのドキュメントIDをこのインデックスから取得できます。
また、MarkLogic では、three-character index を活用してより長いワイルドカードタームを処理できます。*ater* のような4文字のタームは、*ate* と *ter* に分割し、この2つのタームを three-character index で検索して、その結果の共通部分を取ることができます。ただし、これには不適切な結果が含まれている可能性があります。例えば、terminate が誤ってマッチとして判定されるので、この語を含んだドキュメントが結果に含まれる可能性があります。
このような不適切な結果は、検索のフィルタリングの段階で削除します。フィルタリングでは、結果のドキュメントを開いて、それらのドキュメントが検索クエリに実際にマッチすることを再確認します。MarkLogic で実行されるフィルタリングが増えると、結果を返すまでにかかる時間が長くなります。したがって、フィルタリングに時間がかかる可能性がある長いワイルドカードタームを three-character index で処理するのは、必ずしも得策ではありません。(フィルタリングはオフにできます。これによって結果をより速く取得できますが、不適切な結果が含まれている可能性があります。)
MarkLogic には、データベースの1文字インデックスおよび2文字インデックスをオンにするオプションもあります。より短いタームに対するワイルドカードの結果(例:b* や ba*)を取得するのに役立つように思えるかもしれませんが、これらのインデックスをオンにすると、インデックスが非常に大きくなるので、ドキュメントの読み込み、インデックス付け、およびマージにかかる時間に悪影響を及ぼします。したがって、これらのインデックスはアクティブにしないことを推奨しており、以降の説明では、これらはオンになっていないものと仮定しています。
4文字以上のシーケンスに対するインデックスはどうなっているのでしょうか。MarkLogic では、それらのインデックスは提供されていません。これは、多くの場合、それによって得られるメリットよりも、インデックススペースが増大するデメリットのほうが大きいからです。一般的に、労力に対する成果が最も大きいのが three-character indexes で、これによってワイルドカードおよび検索全般を効率的にサポートできます。
Trailing Wildcard Index
4つ以上の文字と末尾の * からなるワイルドカード検索をすばやく処理できるように、trailing wildcard index をオンにすることができます。このインデックスでは、3文字以上のそれぞれの語に対して、プレフィックスのすべての可能な組み合わせがエントリとして保存されます。例えば、cater に対して、cat、cate、および cater がインデックスに保存されます。このインデックスには、シーケンスが語の先頭に存在していたことを示すコンテキスト情報が含められます。cate* を検索すると、MarkLogic で trailing wildcard index が使用されます。
Trailing wildcard index は、タームの先頭に * が付いている場合(例:*ater)には役立ちません。また、MarkLogic では、trailing wildcard index の逆バージョンである先頭ワイルドカードインデックスは提供されていません(つまり、MarkLogic はこの点で英語寄りの仕様になっています)。英語のタームを検索するときには、ワイルドカードを先頭に付けるよりも、末尾に付けるほうが多くなります。これは、英文法ではプレフィックスよりもポストフィックスのほうが多く使用されるからで、trailing wildcard index を採用しているのはこのためです
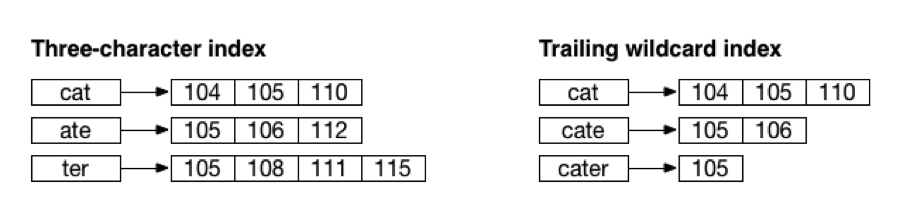
図1:インデックスによって、ドキュメントに存在する文字シーケンスが、対応するドキュメントIDにマッピングされます。この図は、MarkLogic で複数のインデックスがオンになっている場合に、cater という語からシーケンスが保存される様子を示しています。
レキシコン
MarkLogic では、three-character 文字列や trailing wildcard よりも複雑な形のワイルドカード検索に対して、レキシコンの使用が試みられます。レキシコンは、データベース内の一意の語を列挙した順序付きリストです。インデックスとは異なり、レキシコンでは、語をその出現元のドキュメントにマッピングしていません。これは単なる大きな順序付きリストです。
MarkLogic はレキシコンを使用することで、ワイルドカードパターンにマッチする可能性があるすべてのものをすばやく取得できます。例えば、r?b*?t というワイルドカード文字列を検索するとします。MarkLogic は、この文字列を取得して、レキシコンの語のリストと比較できます。レキシコンの語は順番に保存されているので、MarkLogic はそれらを効率的にスキャンできます(これについては後で詳しく説明します)。
この r?b*?t の例では、レキシコンのスキャンによって rabbit、rebuilt、および robot というタームが返される可能性があります。MarkLogic はこの情報に基づいて、ワイルドカードクエリを次のように書き換えることができます。
rabbit OR rebuilt OR robot
その後、インデックスでこの3つの語の出現を検索し、見つかったものを1つの結果としてまとめることができます。
また、レキシコンでは検索ボックスでの入力候補表示もサポートされます。ユーザーが検索ボックスに「vac」と入力すると、アプリケーションがレキシコンを確認して、vacation や vacuum などのマッチする語を列挙したメニューを表示できます。これは vac* を検索するのに似ていますが、インデックスを確認する必要がありません。
レキシコンの制限
レキシコンを使用して、OR で連結されたクエリに展開する方法は、いつもうまくいくとは限りません。ワイルドカード文字列に対してレキシコンから何千ものマッチするタームが返される場合は、数が多すぎて効果的な OR クエリになりません。
これに対処するために、3文字のプレフィックスおよびポストフィックスからなる短いリストを作成することで、返された大量のタームのリストを切り詰めることができます。
例えば、レキシコンの結果リストが次のようになったとします。
staggeredstairedstammeredstaredstarred
プレフィックス–とポストフィックスの方法を使用すれば、このリストを次のように書き換えて、より短く管理しやすいものにすることができます。
sta**red
その後、これらの3文字シーケンスを使用して、高速に処理される three-character indexes を利用できます。これには不適切な結果が含まれている可能性があり、フィルタリングが必要になりますが、レキシコンをスキャンして返される語が多すぎる場合は、こちらのほうがよい方法になります。
MarkLogic は、a* のような単一の文字と末尾のワイルドカードからなるクエリに対して、さらに別の方法を使用します。MarkLogic は、これを次の3つの別個の検索に分割します。
- 通常の語インデックスを使用して、
aを検索します(aのインデックスエントリは存在しても1つのみです) - レキシコンで
a?を検索してから(返される結果は少数にとどまります)、それらをORで連結して展開したクエリを実行します - レキシコンで、プレフィックスとポストフィックスの方法を使用して、
a??*を検索します(aで始まるマッチした語をリストに大量に列挙するのを避けています)
ワイルドカード検索のオプション
開発者は、lexicon-expand オプションを使用して、MarkLogic でのレキシコンを使用したワイルドカード検索の解決方法を制御できます。このオプションには次の値を使用できます。
heuristic | MarkLogic の内部ルールのセットを使用して、ワイルドカードクエリを解決します(例えば、レキシコンのスキャンで大量のタームが返されることが予想される場合は、別の方法を使用します)。これがデフォルトです。 |
full | ワイルドカードクエリを、OR で連結されたタームのセットに常に展開します。大量のタームが返されてクエリが遅くなる可能性があってもこの処理は行われます。 |
prefix-postfix | レキシコンでマッチしたタームに基づいて、接頭辞と接尾辞のシーケンスを常に使用して、ワイルドカードクエリを解決します。 |
off | レキシコン展開をワイルドカード検索で使用しません。代わりにインデックスを使用します。 |
レキシコンスキャンにおける工夫
レキシコン内のエントリの順序は、レキシコンのコレーションタイプによって決まります。小文字が大文字より前に配列されるコードポイントレキシコンは、検索が早く、より正確な結果が得られるので推奨されます。ただし、大文字と小文字を区別しない検索に対して難点があります。例えば、レキシコンで cat* というワイルドカードタームに対して単純なリニアスキャンを行うと、c で始まるエントリから C で始まるエントリにスキャンが行き着くまでに、マッチしない大量のエントリ(d、e、f などで始まるエントリ)がチェックされることになります。
MarkLogic では、この問題を解決するために、最初に一連のバイナリ検索を行って、スキャンする必要があるレキシコンのセクションを絞り込みます。バイナリ検索では、順序付きリストの中央にある項目を見つけ、検索タームがその中央の項目の前にあるのか後ろにあるのかを調べ、その後、同様の検索を該当する半分に対して実行します。このように分割して絞り込んでいくことで、最後に目的のものにたどり着きます。通常はこのほうが、リニア検索で見つけるよりも早くなります。
cat* のワイルドカード検索では、MarkLogic はバイナリ検索を行って、c* で始まり C* で終わる範囲を見つけます。次に、その範囲の中でバイナリ検索を行って、ca* から cA* のサブセクションと、Ca* から CA* のサブセクションを見つけます。最後に、文字 t および T に対するサブセクションを見つけます(実際には、範囲が十分小さくなった段階で、検索ターム内の文字に対するバイナリ検索を打ち切ることがあります)。サブセクションが特定されたら、それらをすばやくスキャンして、マッチするエントリを見つけることができます。
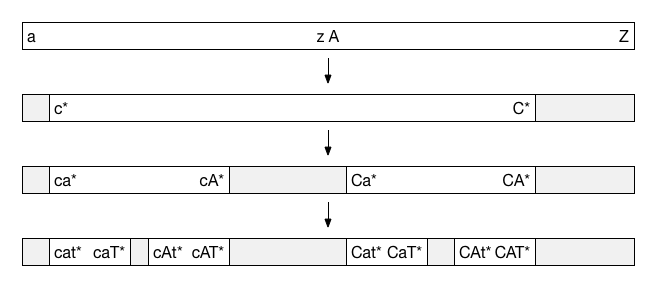
図2:MarkLogic は、一連のバイナリ検索を使用して、レキシコン内でタームをスキャンする労力を最小化します。この例は、cat* というタームに対して大文字と小文字を区別しない検索を行う場合の処理を示しています。白いセクションが、マッチが存在する可能性がある領域を示しています。
まとめ
MarkLogic では、非常に複雑なワイルドカードクエリにもすばやく結果を返すことができます。ワイルドカード検索の詳細、および関連設定の構成の詳細については、MarkLogic のマニュアルを参照してください。
この記事の執筆にあたって援助をご提供いただいた Mary Holstege 氏と Fei Xue 氏に感謝します。

マイク・ウールドリッジ
Mike Wooldridgeは、MarkLogicのシニアソフトウェアエンジニアです。彼は、Monitoring Historyを含むMarkLogicに付属するソフトウェアツールのいくつかを構築し、MLPHPなどのオープンソースプロジェクトを作成しました。Mike は Inside MarkLogic Server の最新版の共著者であり、Teach Yourself VisualPhotoshop CC や Teach Yourself VisualHTML5など、グラフィックソフトウェアとウェブデザインに関する本を Wiley に書いています。


