
(このブログは2017年に掲載されたものの日本語訳です)XQueryコードを最適化するためのわかりやすい手順があったらいいと思いませんか。今回はそれをご紹介します。ここでは、XQueryを使用する際に参考となるチェックリストをご紹介します。
#1 – クエリを「間違って」updateモードで実行しているかどうか
MarkLogicは、 queryとupdateの2つのいずれかのモードでトランザクションを実行します。主な違いとして、queryトランザクションは読み取り専用(read-only)で更新ができないのに対し、updateトランザクションでは更新ができます。
これが私のリストのNo.1となります。というのも、私自身が誤ってコードをupdateモードで実行してしまうことが多く、そのためにパフォーマンスが大幅に低下することがあるからです。しかしこれから紹介するように、これはとても簡単にチェックできます。
これがパフォーマンスに及ぼす影響
その話に入る前に、データベースのデータを更新するには、update(更新)ステートメントが必要なことを知っておいてください。これは絶対に使いたいものですし、使う必要があります。
しかし、場合によってはコードを実行しても何も更新されないこともあります。このような「クエリのみ」のコードは、queryモードで実行すべきです。ここでは、必要がないのにクエリを誤ってupdateモードで実行してしまっている場合を考えてみます。
updateモードで実行した場合、MarkLogicは適宜「読み取りロック」と「書き込みロック」を適用します。間違ってトランザクションをupdateモードで実行してしまうミスはよくあります。これによって、パフォーマンスが大幅に低下する可能性があります。例えば、以下のクエリを見てみましょう。
for $doc in fn:doc() where $doc/root/selected = true() return $doc
fn:doc()は、パラメータが与えられない場合、データベース内のすべてを返します。このコードがupdateモードで実行されると、「ドキュメントを更新したい」のだとMarkLogicは想定し、fn:doc()で返されるすべてのドキュメントをロックします。また、 書き込みロックは排他的なため、マルチスレッドのリクエストはすべて、ロックの奪い合いをします。ロックの競合は正常であり、当たり前のように発生しますが、これによりパフォーマンスが低下する可能性があります。これは単純な例ですが、言いたいことはわかってもらえたかと思います。本当は必要ないのに、間違ってupdateモードでコードを実行してしまうと、パフォーマンスに問題が生じてしまうのです。
updateモードかどうかの確認方法
幸いなことに、本当はqueryモードで実行すべきなのに間違ってupdateモードで実行している場合にエラーを発生させる、うまい方法があります。
let $assert-query-mode as xs:unsignedLong := xdmp:request-timestamp() for $doc in fn:doc() where $doc/root/selected = true() return $doc
ここで重要なのは、letステートメントです。
let $assert-query-mode as xs:unsignedLong := xdmp:request-timestamp()
xdmp:request-timestは、queryモードで実行するとxs:unsignedLongを返します。しかし、updateモードで実行するとempty-sequence()を返します。このletステートメントは、updateトランザクションから実行すると、empty-sequence() からxs:unsignedLongへのキャストに失敗するため、例外が発生します。
クエリを実行して例外が発生した場合は、updateモードで実行していることがわかります。この場合、原因を突き止めて、このコードをqueryモードで実行できるように修正しなければなりません。
それでは、どうしてこのような不必要なupdateモードになってしまっているのでしょうか。
間違ってupdateモードになってしまう可能性のあるシナリオをいくつかご紹介します。
- xdmp:eval、xdmp:invoke, xdmp:invoke-function、xdmp:spawn、xdmp:spawn-functionという関数は、コードを実行したり、トランザクションモードの設定オプションを指定したりするものです。これらのいずれかの関数でコードを実行している場合、誤ってupdateモードに設定されていないかどうかを確認してください。
- REST APIサービス拡張。MarkLogicのREST APIでは、独自のサービス拡張を定義できます。まず、1つまたは複数のエントリポイント関数(get、post、put、deleteなど)を持つxqueryライブラリモジュールを作成します。これらの関数の中には、デフォルトでqueryモードで動作するものと、updateモードで動作するものがあります。詳細は、REST APIのドキュメントを参照してください。次に、デフォルトではupdateモードで実行されるメソッドでコードを実行しているかどうかをチェックします。
- 静的分析。トランザクションが「自動」に設定されている場合、updateモードとqueryモードのどちらで実行するかはMarkLogicが決定します。どちらで実行すべきかを判断を下すために、MarkLogicは使われているコードに対して静的分析を実行し、更新を実行する何らかの関数への呼び出しがあるかどうかを確認します。これらの関数のいずれかがコードパスに見つかった場合、MarkLogicはupdateモードで実行されます。
以下は、updateモードとなるコードの例です。
let $assert-query-mode as xs:unsignedLong := xdmp:request-timestamp() return if (fn:false()) then xdmp:document-insert("/test.xml", <test>This never gets called</test>) else "query mode stuff"ご覧のとおり、実際にはdocument-insertは呼び出されませんが、MarkLogicはコードパスの中でこの関数を認識しているため、updateモードで実行されます。
MarkLogicのマニュアルには、トランザクションに特化した章があります。これを最低1年に1回は読むようにお薦めします。
#2 – cts:searchをフィルタリングなしで実行しているかどうか
私のリストのステップ2は見落とされがちですが、幸いなことにすぐに簡単に修正できます。
MarkLogicの最も有名なAPIの1つに、cts:searchがあります。MarkLogicを開発したことがある人は皆、どこかで使ったことがあると思います。もしこれを使った際に検索が遅いと感じた場合、間違って「フィルタリングあり検索」を実行していないかどうかを確認してください。
それでは「フィルタリングあり検索」とは何でしょうか。
スコット・パーネル氏は、2016年11月のブログ『A goal without a plan is just a wish(計画のない目標はただの願い事 )』で、これをうまく説明しています。
デフォルトでは、
cts:searchは2つのフェーズでクエリを解決します。第1段階では、Dノードのインデックス解決を行います。この最初の結果には、インデックスの構成やクエリによっては偽陽性(false positive:本当はそうでないのにそうだと判断されたもの)を含む可能性があります。第2段階では、Eノードで結果のフィルタリングを行い、マッチしたドキュメントを検証して偽陽性を除去します。インデックスだけでクエリを完全に解決できるのであれば、フィルタリングは不要です。
「インデックスが適切に設定されているのでフィルタリングなしで実行したい」という前提で、 cts:searchをチェックしていきます。
cts:searchのマニュアルを見ると、この関数のシグネチャがわかります。
cts:search( $expression as node()*, $query as cts:query?, [$options as (cts:order|xs:string)*], [$quality-weight as xs:double?], [$forest-ids as xs:unsignedLong*] ) as node()*
cts:searchをフィルタリングなしで実行するには、3つめのパラメータのオプションとして「unfiltered」を指定する必要があります。
cts:search(fn:doc(), $query, ("unfiltered"))ここで確認しておきたいのは、cts:searchのデフォルトがフィルタリングあり(filtered)であることです。unilteredパラメータを指定しないかぎり、デフォルトである「フィルタリングあり」の挙動となります。
#3 – コードをプロファイリングする
コードが期待通りに動作しない場合は、 必ずプロファイリングを行ってください。プロファイリングをせずに最適化しないでください。間違ったものを修正して時間を無駄にしてしまう可能性が高いからです。
幸いなことに、MarkLogicではこれを簡単に行うことができます。
最も簡単な方法:クエリコンソール(QConsole)を使用する
MarkLogicマニュアルによると:
クエリコンソールはインタラクティブなwebベースのクエリ作成ツールです。クエリをアドホックにXQuery/サーバーサイドJavaScript/SQL/SPARQLの形式で記述・実行できます。クエリコンソールを使うと、コードの一部のテスト、デバッグ、クエリのプロファイリング、管理用のXQueryスクリプトの実行などができます。
QConsoleはhttps://yourserver:8000/qconsole/にあります。
プロファイル用のボタンを使うと、クエリで最も時間がかかっている場所がわかるので、簡単にクエリを実行できる場合には朗報です。
実行したいコードを入力し、Profileタブを選択し、Runボタンをクリックするだけです。
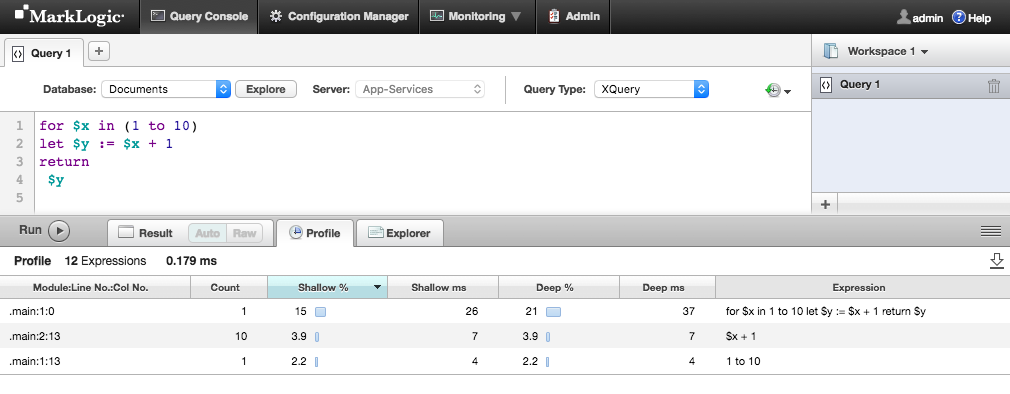
表の結果は、実行時間の長いものから短いものの順に並べられています(Shallow %)。実行に異常に時間がかかっているステートメントを探し、それをどのように最適化できるかを考えます。
もうちょっと難しい方法:prof:enable()とprof:report()を使用する
何らかの理由で、QConsoleでコードを実行できない場合があるとします。ご心配なく。以下の関数を使うことができます。
以下のようにコードをラップするだけでOKです。
prof:enable(xdmp:request()), for $x in (1 to 10) let $y := $x + 1 return $y, prof:disable(xdmp:request()), prof:report(xdmp:request())
prof:report()の出力は、XML版のプロファイルレポートです。コードが他のコードの中に深く埋もれている場合は、xdmp:logでログを記録するか、xdmp:document-insert()でドキュメントに挿入して後から見ることができます。
凝ったことが好きな人は、関数を作ることで、再利用可能なモジュールを作成して、それをログに記録させることもできます。
(: name this file something like /path/to/profiler.xqy :) xquery version "1.0-ml"; module namespace profiler = "https://marklogic.com/profiler"; declare function profiler:profile($func) { let $req := xdmp:request() (: start profiling :) let $_ := prof:enable($req) (: call the code to profile :) let $result := $func() (: stop profiling :) let $_ := prof:disable($req) (: create the profile report :) let $report := prof:report($req) (: save report somewhere :) let $_ := xdmp:document-insert("/profile-output/" || fn:string($req) || ".xml", $report) (: log it too :) let $_ := xdmp:log(xdmp:describe($report, (), ())) return (: return the output, if any, from your profiled code :) $result };これはかなり凝っていますね。これはどのように使うのでしょうか。
import module namespace profiler = "https://marklogic.com/profiler" at "/path/to/profiler.xqy"; profiler:profile(function() { (: put your code in here :) for $x in (1 to 10) let $y := $x + 1 return $y })このコードを実行すると、プロファイラレポートがErrorLogに記録され、/profile-output/${requestid}.xmlに挿入されます。QConsoleの出力のように読みやすくはありませんが、同じ情報がすべて含まれています。
#4 – 適宜インデックスを使用する
MarkLogicでは、2つのフェーズでクエリを実行します。第1段階は高速で、インデックスを使って検索結果を絞り込みます。この最初の結果には、インデックスの構成やクエリによっては偽陽性が含まれる可能性があります。第2段階では、結果をフィルタリングします。この第2段階では、ドキュメントをディスクから取り出し、それがクエリにマッチするかどうかを検証します。マッチしなかったドキュメント(偽陽性)は結果セットから削除されます。ドキュメントを取得する際にディスクI/Oを使用するので、これがクエリの実行速度を低下させる原因となることが多いです。
多くの場合、インデックスのみに頼ることで、第2段階を回避できます。MarkLogicでは、まさにこれを実行するためにcts名前空間およびxdmp名前空間内の多くの関数を公開しています。
シンプルな例
よくある例として、クエリにマッチするドキュメントの件数を把握するというものがあります。
fn:count(/customer[@paid=fn:false()])
これは、paid=”false”属性にマッチするすべての顧客をディスクから取得する必要があるため、パフォーマンスが低下します。これを高速化するには、代わりにインデックスを使用します。
xdmp:estimate(/customer[@paid=fn:false()])
ここでxdmp:estimateを使用していることに注意してください。これが速いのは、フィルタリングなしで実行しているためです。つまり、クエリ解決の第2段階を実行しません。このため名前が「estimate(想定)」なのです。これはインデックスに基づいて件数を算出しています。結果が正しい値となるようにするには、インデックスを適切に設定する必要があります。
#5 – cts:searchをインデックスで最適化する
上記の1~4の手順の後に、パフォーマンスのボトルネックがcts:searchのコードにあることがわかった場合は、インデックスの最適化を検討することになります。この方法については、2016年11月のスコット・パーネル氏のブログ記事『A goal without a plan is just a wish』に詳しく書かれていますので参照してください。
さらに詳しく
このチェックリストは、MarkLogicの開発者がパフォーマンスの問題を発見して修正する方法の一部を示しています。この記事で取り上げたトピックについてもっと知りたい場合は、以下を参照してください。
- 『Performance: Understanding System Resources』 (ホワイトペーパー)
- 『インサイドMarkLogicサーバー』(ホワイトペーパー)
- 『A goal without a plan is just a wish(計画のない目標はただの願い事)』(ブログ)
- 『Query Performance and Tuning Guide』(マニュアル)
- 『Understanding Transactions in MarkLogic Server』(マニュアル)
Paxton Hare
View all posts from Paxton Hare on the Progress blog. Connect with us about all things application development and deployment, data integration and digital business.


