
昨今、マイクロサービスへの関心が高まっています。マーティン・ファウラーによると、マイクロサービスアーキテクチャとは、「ソフトウェアアプリケーションを、独立してデプロイ可能な個々のサービスの集合体としてデザインする」方法のことです。
マイクロサービスにより、一般公開サイトや社内システムの機能を継続的に増やし続けられるとされていますが、これは小規模かつ独立した機能を定期的に追加することで実現されます。このアプローチは、大規模なモノリシックなアプリケーションのやり方とは対照的です(モノリスにおいては変更のエンジニアリング/テスト/デプロイは簡単ではありません)。個人的には、マイクロサービスのメッセージは説得力があると思いますが、そこにいくつかの落とし穴もあると考えています。例えばポリグロット・パーシステンスの問題などがあります。
ポリグロット・パーシステンスの長所として、各サービスに合わせて最も効率的なデータ格納方法を選択できることがあります。テキストファイルからセマンティックデータベースまで、さまざまな選択肢の中から選べます。これは、作業目的ごとに適切なツールを選択できるという点で優れています(何でもかんでもリレーショナルデータベースに入れようとしてうまくいかなかった、というケースは驚くほどたくさんありますし)。一方、各サービスごとに個別のストレージやデータベースを立てた場合、それらの保守は悪夢のように面倒になることも事実です。従来は、「アプリケーションごとにデータベースを準備する」方法が一般的であり、この結果、データベースが大量発生していました。現在、多くの企業がこういったデータベースの整理・統合を進めているところです。どのアプリケーションでどのデータを使っているのかの把握も困難になります。またどのデータが「正式/決定版」なのか、あるいは(正式/決定版でないとしたら)どのような状態のデータなのかということの把握も容易ではありません。
悪いパーシステンス
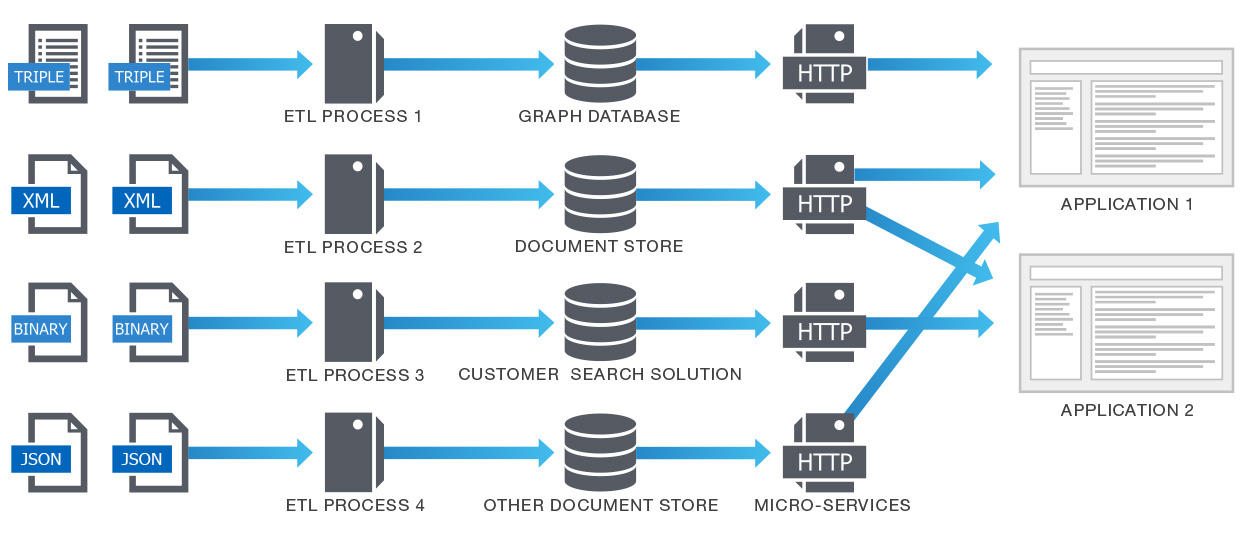
データの種類に応じて、別個のデータベースが使用されます。これにより多くの問題が発生しますが(可用性など)、これらの問題は個々のデータベースにおいて解決する必要があります。また各データベースごとに複数のセキュリティモデルを使用します。こういったデータベースを1つ1つきちんと運用できるでしょうか。
ポリグロット・パーシステンスをどのように扱うのか
私は最近、あるお客様用にPOCをやりましたが、その際、複数の異なるデータソースを扱うデータリッチなエンタープライズダッシュボードを短期間で構築しました。いくつかのビューには、複数サービスからのデータが含まれています。これらのデータはリレーショナルデータベース、PDF、セマンティックデータなどからインポートされたものです。こういった多種多様なデータすべてが、MarkLogicデータベースに入れられています。MarkLogic上に組み合わせ可能な小規模の一連のサービスを構築することにより、アジャイル性および生産性が高まりました。
これらのデータは一か所に集められ、分断が解消されています。以前は、価値のあるデータがシステム内(エンタープライズモデリングツールなど)に閉じ込められていました(これらのシステムはデータベースではありませんが、エンタープライズシステムに関する豊かな情報を含んでいました)。今は、あらゆるデータは「マイクロ」(=小さくて、互いに独立している)な一連のサービスからアクセス可能になっただけでなく、データ統合によるメリットも享受できます。これらのデータは一か所にあり、出自(どこから来たのか/いつ来たのか)も確認できるのです。
良いパーシステンス
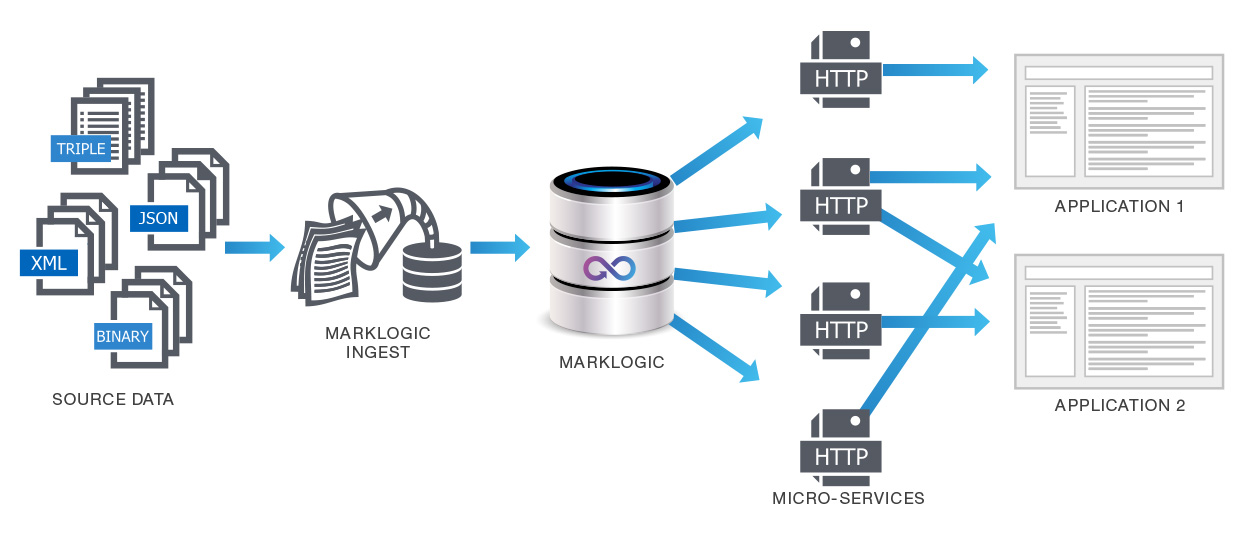
さまざまなタイプのデータがMarkLogicデータベース内に入れられています。MarkLogicはクラスタリング構成であり、可用性に優れ、サポートされています。多くの問題点(可用性など)は一気に解決します。一貫性のあるセキュリティモデル1つで対応でき、ベンダーとのサポート契約も1つで済みます。
アプリケーションのニーズに応えるため、各形式のデータごとに特化したデータベースを準備してデータを格納する必要はありません。MarkLogicでは柔軟なデータモデルにより、この同一のシステム内に異なる種類のデータを格納できます。XMLドキュメントだけでなく、JSONドキュメント、バイナリ、テキスト、セマンティックトリプル、さらにはリレーショナルデータまで扱うことができます。各データタイプごとに別個のソリューションを複数準備する代わりに、MarkLogic1つですべてに対応します。これにより「ポリグロット(=多様)」なデータを扱うことができ(素晴らしいです)、「ポリグロット」なベンダーや実装(ダメです)を回避できます。
プロジェクトにおいて各データタイプごとに違うベンダーを採用していたら(さらに各マイクロサービスごとだったらもっと大変ですが)、ITコストは間違いなく跳ね上がってしまうでしょう。また業務部門からのニーズに応えようとして、「ちょっと」データベースやサービスを追加することによる長期的および短期的コストも忘れないでください。またこういったサービスは、本番稼働を開始した瞬間にレガシーなインフラとなってしまいます。ポリグロットなベンダーを使わない、マイクロサービスやポリグロットなデータを考えるべきです。ここでの目的は、新機能の礎となるものを生み出したり、コストを削減したり、売り上げを拡大したりすることであり、予算を食いつぶしかねないものを導入することではないのですから。

ポール・ヘーネ
View all posts from ポール・ヘーネ on the Progress blog. Connect with us about all things application development and deployment, data integration and digital business.


