MarkLogic Data Hub エンティティについて
※本記事の内容は、Data Hub v5.2.1を前提としています。
今回のエントリでは、MarkLogic Data HubにおけるEntityについて、掘り下げていきたいと思います。 既にMarkLogic Data Hubの概要および、フローやステップに関する基礎知識をお持ちの方を読者対象としておりますので、これからMarkLogic Data Hubについて学ばれるという方は、下記のドキュメントやチュートリアルを先にご参照ください。
・Data Hub QuickStart チュートリアルhttps://www.progress.com/jp/blogs/data-hub-quickstart-tutorial
・MarkLogic Data Hubドキュメンテーション日本語版: https://developer.marklogic.com/learn/data-hub-quickstart-jp/ 英語版(最新): https://docs.marklogic.com/datahub/
エンティティについて
エンティティは、エンタープライズ内の高レベルのビジネスオブジェクトです。例えば、従業員、製品、発注書、部署などです。 MarkLogic Data Hubでは、MarkLogicのエンティティサービスを使用して、ビジネスエンティティのモデルを作成し、こうしたモデルに基づいてコードの一部の生成、データベース設定、インデックス設定、検証を行えます。
例えば、データモデリングの結果、従業員と部署の2つのエンティティが必要となったとします。その場合、従業員エンティティ用、部署エンティティ用の2つのエンティティ設定をMarkLogic Data Hub上で実施します。
外部に公開されるデータやマッピング機能の対象となるデータに対しては、エンティティを作成することを推奨します。これによる開発生産性や運用性の向上を期待できるためです。 逆に全てのデータに対してエンティティを定義する必要はありません。例えば生データに対してエンティティを定義したところで、MarkLogic外部からの直接のデータアクセスがないため、エンティティ設定の恩恵が少なく、手間だけがかかります。
本ブログ執筆時点でのエンティティ設定の恩恵は、TDE定義の自動作成やマッピングステップの利用の2点が大きいです。 今後のアップデートによりエンティティの設定を前提とした機能が増えていくこと予想されますので、現時点での恩恵が少なかったとしても将来のためにエンティティを設定しておくことを強く推奨します。
エンティティの設定
Quick Startを利用する事で簡単にエンティティを設定できます。
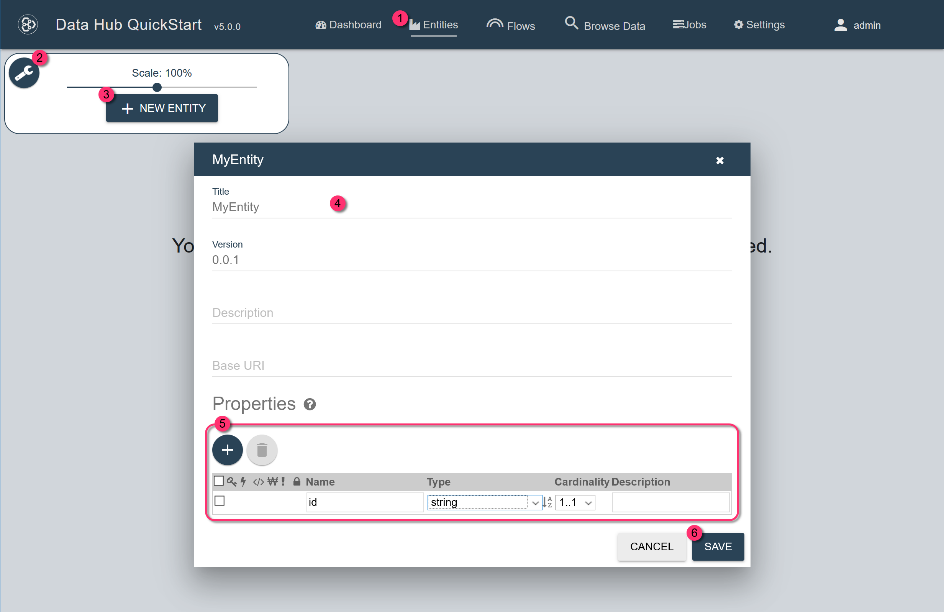
- QuickStartのナビゲーションバーで、[Entities]をクリックします。
- レンチのアイコンをクリックして、エンティティツールコントロールを開きます。
- [+ NEW ENTITY]をクリックします。
- [New Entity]フォームの[Title]で、エンティティの名前を設定します。
- [Properties]で、データソース間で標準化するデータフィールドを追加します。
プロパティの設定
ここでは、前節「エンティティの設定」における手順5プロパティ設定の内容を深掘りします。 プロパティでは、アプリケーションで使用可能にする情報のフィールド名とデータ型を宣言します。ここで定義された内容は、TDEやマッピングステップなどで利用されます。
| プロパティ | 説明 |
| 名前(Name) | アプリケーションがこのデータにアクセスするために使用する名前。TDEやマッピングステップの列名としても利用されます。 |
| 型(Type) | アプリケーションがこのデータに対して予測する型。レンジインデックスを付与する際の型、TDE経由でSQLアクセスされる際の型など、様々な形で利用されます。 |
| カーディナリティ(Cardinality) | 対象のプロパティが複数の値を持つ場合、1..∞を選択します。それ以外の場合は、1..1を選択します。
例えば、連絡先というプロパティがあり、中身が[080XXXX1234, 080XXXX1235, 080XXXX1236]のように複数の値から配列の形式で格納したいとします。その場合は、1..∞ を選択します。 |
| 説明(Description) | (オプション)エンティティプロパティの説明 |
| インデックス設定 | インデックス設定アイコンの説明については、次のトピックの内容を参照してください。
|
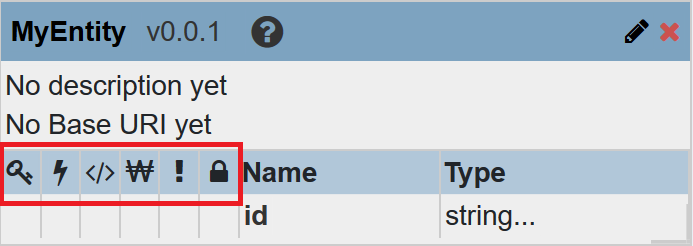
インデックスの設定
| アイコン | 名前 | 効果 |
 | 主キー | このプロパティはインデックス付けの主キーとして使用されます。
主キーを設定出来るプロパティは1つのみです。TDEを利用する場合に必須のプロパティです。 |
 | エレメントレンジインデックス | 対象プロパティにエレメントレンジインデックスが付与されます。
エレメントレンジインデックス付与の代表例 ・ 範囲検索を実施する場合(1990 < 誕生日 <=2000を条件とした範囲検索) ・ ソート(入社年月日順で検索結果をソート) ・ ファセットの作成 ・ クエリの高速化のため 本設定はデータベース内の全てのドキュメントに対して有効です。例えばあるエンティティで”rating”というプロパティに対してエレメントレンジインデックスの設定を有効にした場合、データベース内の全てのドキュメントに含まれるrating要素がインデックスの対象となります。 |
| パスレンジインデックス | 対象プロパティにパスエレメントレンジインデックスが付与されます。
用途としてはエレメントレンジインデックスと概ね同様ですが、エレメントレンジインデックスが要素を対象とするのに対して、パスレンジインデックスはパスを対象とします。 例えば”rating”というプロパティに対してパスレンジインデックスの設定を有効にした場合、instance/<エンティティ名>/ratingの要素(パス)に対してのみインデックスが作成されます。 | |
 | ワードレキシコン | 対象プロパティを元にワードレキシコンが作成されます。ワードレキシコンは簡単に説明すると、重複無しの値のリストです。
例えば、EmployeeエンティティにおいてLastNameプロパティのワードレキシコンを有効にしたとします。その場合、重複無しの名字(LastName)のリストがデータベース内にレキシコンとして作成されます。 レキシコンは様々な用途で利用できますが、代表的な使用例としてはファセットで利用できます。レキシコンとファセットの関係については時節の内容を参照してください。 |
| 必須プロパティ | 値の存在が必須のプロパティに対して本設定を有効にします。
複数のプロパティを必須に設定できます。 | |
 | PII | 特定のユーザのみが参照できるプロパティを設けたい場合、この設定を利用します。PIIのチェックが有効になっているプロパティに対しては、pii-readerロールに属しているユーザのみが値を参照できたり、検索にヒットさせることが出来ます。pii-readerはデフォルトで存在するロールです。
クレジットカード番号や連絡先などの個人情報項目に利用されることが多いです。 |
ファセットとレキシコンの関係
ファセットとはファセットナビゲーションの略で、Webサイトにおけるナビゲーションの一種です。 ワード検索とは異なり、ユーザが使いやすそうな検索条件をサイト側が用意することによって、ユーザはそれを活用した検索ができるという仕組みです。 MarkLogicではデータベース内に格納されたドキュメントを元にファセットを自動で作成することができます。
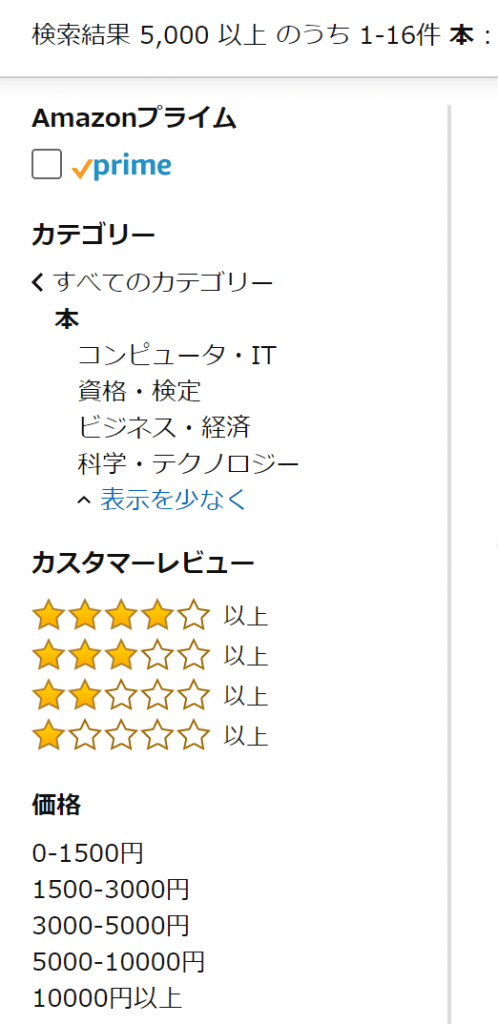
MarkLogicではレキシコンを利用して、ファセットを作成します。レキシコンには様々な種類があります。ここでは代表的なワードレキシコンとレンジレキシコンの説明をします。 ワードレキシコンは単語の一覧からなるシンプルなレキシコンです。 プロパティ設定におけるワードレキシコンのチェックを有効にすると作成されます。ワードレキシコンを有効にすることで、下記のようなカテゴリのファセットを作成できます。
カテゴリ・コンピュータ・IT ・資格・検定 ・ビジネス・経済 …
レンジレキシコンは範囲を持ったレキシコンです。プロパティ設定におけるレンジインデックスやパスレンジインデックスのチェックを有効にすると作成されます。レンジレキシコンを有効にすることで、下記のような価格のファセットを作成できます。
価格・0-1500円 ・1500-3000円 ・3000-10000円 ・10000円以上
TDEテンプレートの自動作成
本記事の執筆時点における、エンティティ作成による最大のメリットといえる、TDEテンプレート自動作成機能について説明します。 TDEを簡単に説明すると、マークロジック内の非構造化されたデータを構造かされたデータとして扱うための機能です。 ここでは、非構造化データをJSON形式のドキュメント、構造化データを表形式のドキュメントと考えるとわかりやすいです。
非構造化データに対してTDEテンプレートというものを作成すると、そのデータをRDBMSの表形式のような形で扱うことができ、外部システムからSQLアクセスが可能となったり、TableauやPower BIなどのツールからの直接アクセスが可能となったりします。 TDEテンプレートは作成したエンティティをベースにMarkLogicが自動でを自動で作成してくれます。(Data Hub Framework 5.2.1の新機能)
本記事の冒頭で、エンティティ作成の重要性をお伝えしました。 エンティティを作成することで、TDEのテンプレートが自動で作成され、外部アプリケーションからのアクセス性が図らずとも向上するという非常に便利な機能となっておりますので、この機能を是非ともご活用ください。
Tableau連携の例
TDEの動作サンプルとして、Tableau連携の設定と動作を紹介したいと思います。 TDEを利用する事により外部ツールからMarkLogicへのODBC接続が可能です。言い換えると、ODBC接続が可能でSQLアクセスが可能なツールであれば、SQLやツールの機能を利用してMarkLogic上のデータにアクセスすることができます。 ここではTableauからのアクセス例を紹介します。Tabelauは標準でMarkLogicへのアクセスをサポートしていますが、中ではODBC接続を介してのSQLアクセスを実施しています。
手順
- エンティティの作成(MarkLogic上の設定)
- MarkLogic上での動作確認
- ODBCサーバの設定(MarkLogic上の設定)
- Tableauの設定(Tableau上の設定)
- Tableau上でのデータ表示(Tableau上の設定)
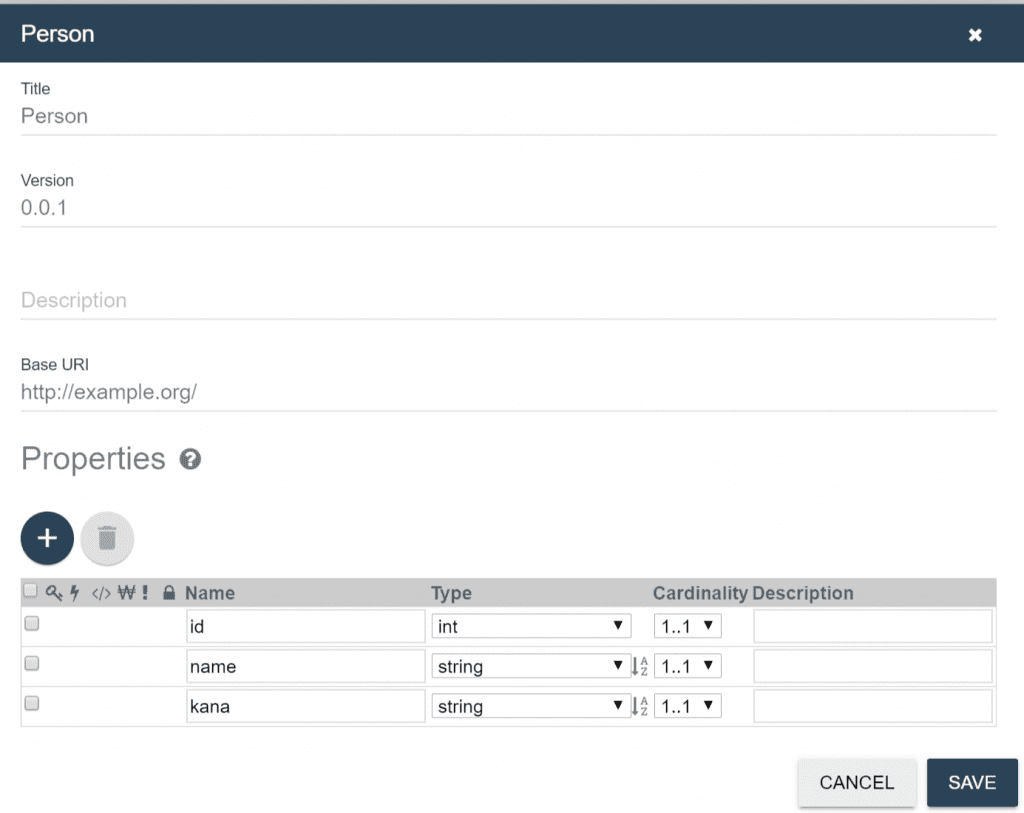
1. エンティティの作成
エンティティを作成します。ここでは例として、idとnameとkanaを持つエンティティをPersonという名前で作成します。 これによりPersonというTDEテンプレートも自動で作成されます。
2. MarkLogic上での動作確認
エンティティ作成後、Tableauからのアクセス前にMarkLogicのクエリコンソール上で動作確認をします。 本内容は必須の手順ではありませんが、本トピックの内容を皆様により理解頂けるように記載しております。 テスト用のデータは以下の設定でdata-hub-FINALデータベースに格納しています。 マッピングステップの設定において、手順1で作成したPersonエンティティを指定している事に注意してください。
2-1 : データの投入
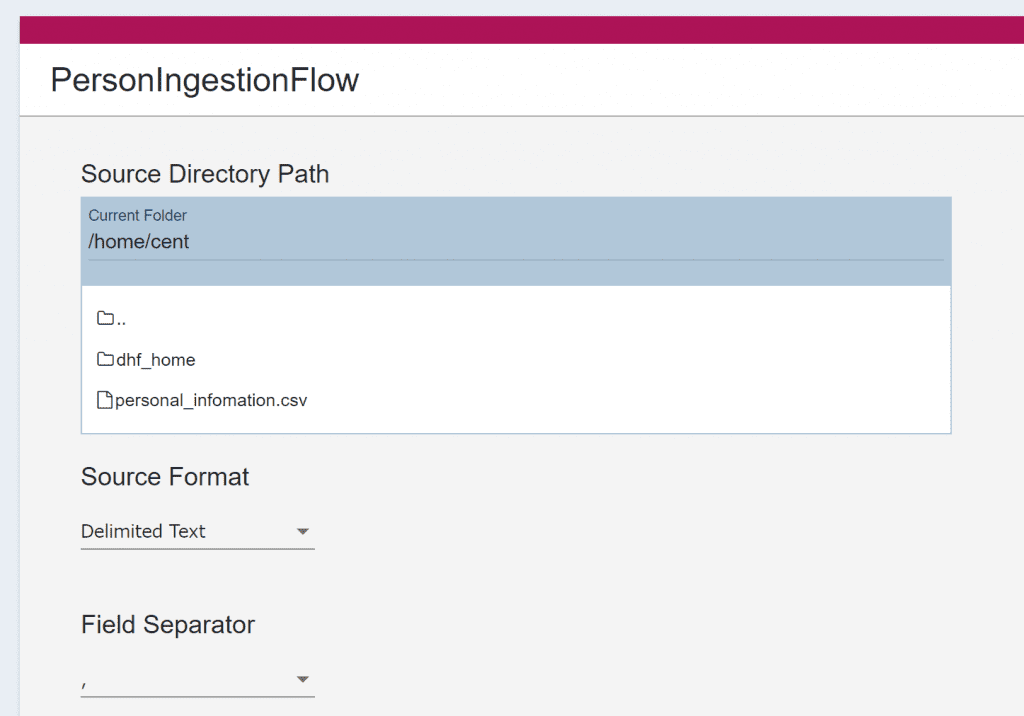
ここではIngestion stepを利用して、CSVのデータをJSON形式でdata-hub-STAGINGデータベースに格納しています。 以下の設定以外はデフォルトの設定となります。
2-2 : データの加工
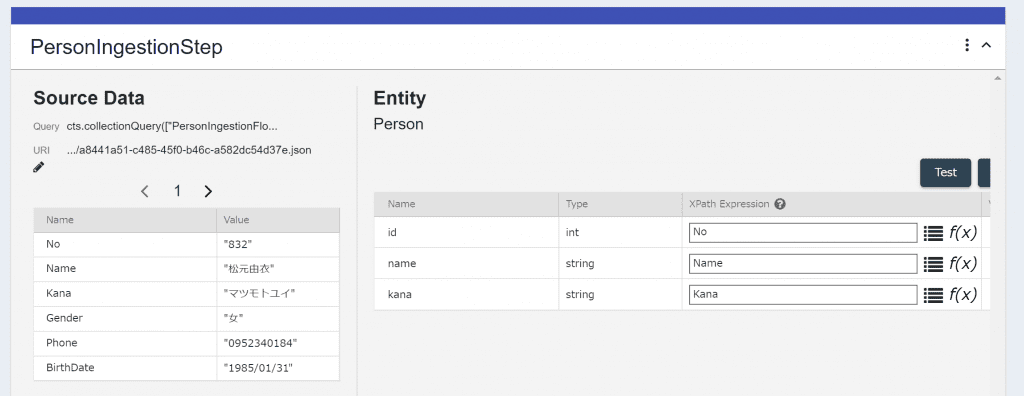
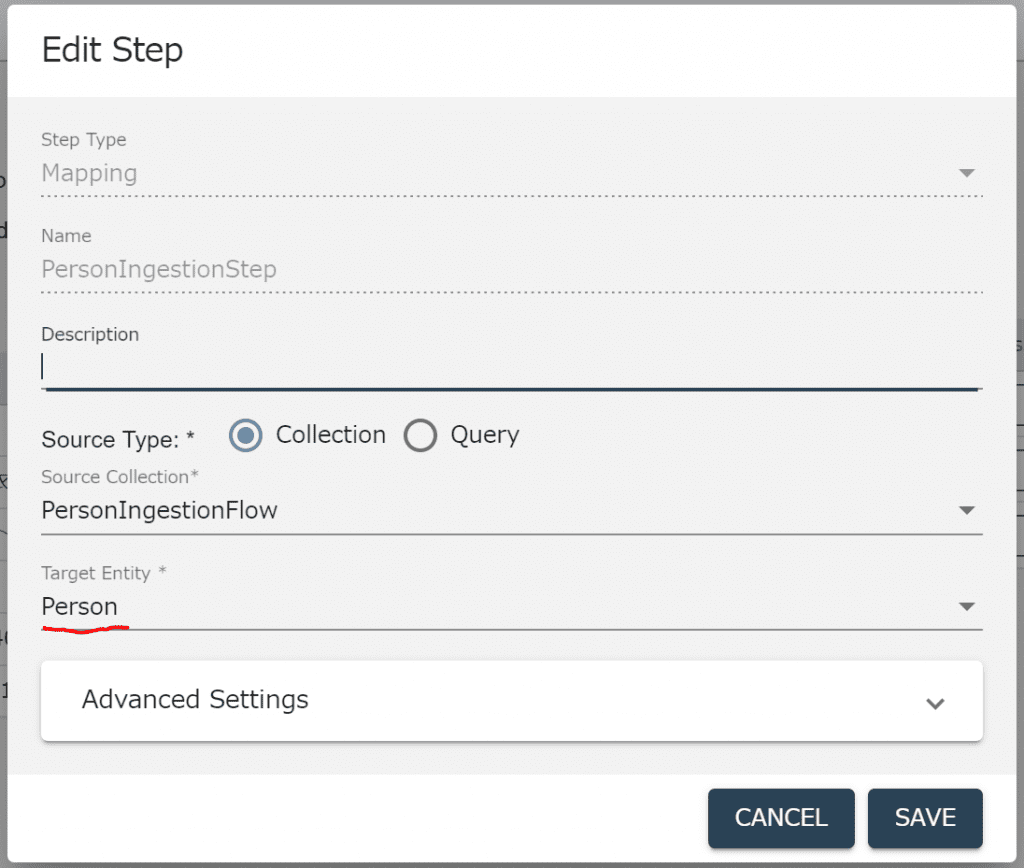
Stagingデータベース上の生データを加工して、Finalデータベースに保存します。 以下の設定以外はデフォルトの設定ととなります。Target EntityがPersonとなっていることで、TDEのテンプレートと実際のデータが紐付けされます。
2-3 : Ingestion, Mapping stepの実行
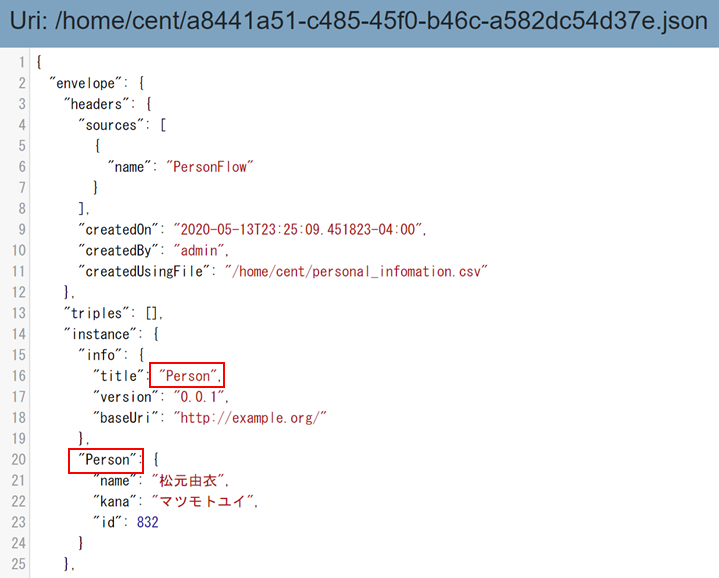
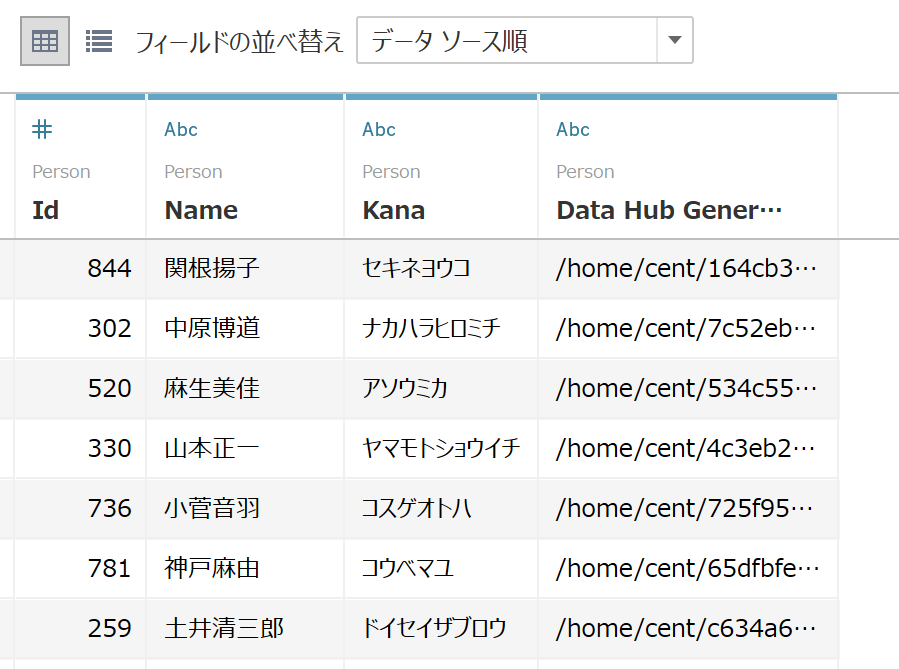
Runボタンを押してIngestion stepと Mapping stepを実行します。結果、加工されたデータがFinalデータベースに保存されます。 実際のデータを見てみると、エンティティ名のPersonがデータの内容に反映されています。
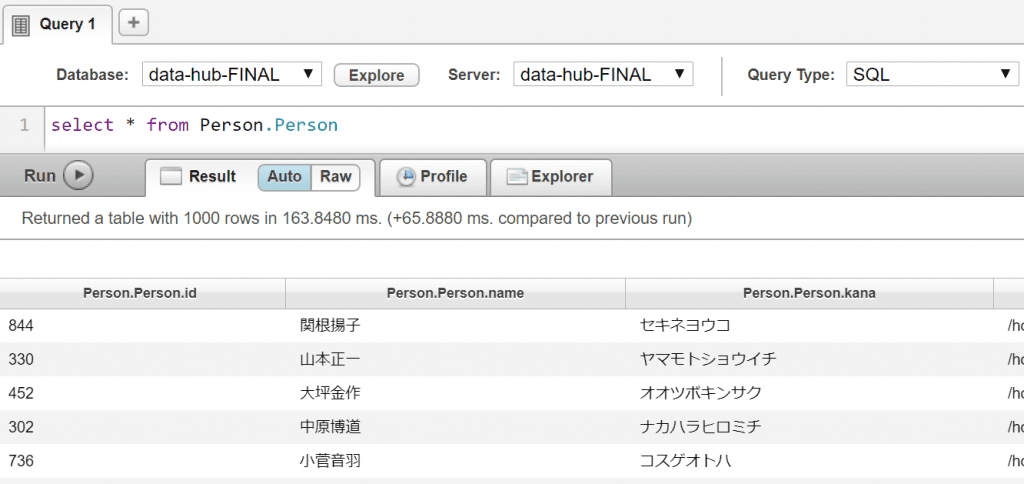
2-4 : SQLの発行
クエリコンソールにて、Databaseがdata-hub-FINAL、Query TypeがSQLとなっていることを確認して、以下のSQLをRUNボタンで実行します。 Person.Personが対象エンティティのTDEテンプレートにおけるビュー名となります。自動作成されたTDEテンプレートによるビュー名は、<エンティティ名>.<エンティティ名>のようになります。
ここで利用するユーザには、flow-operator(読み込みのみ)またはflow-developer(更新も可能)のロールが付与されている必要があります。Adminロールだけでは不十分となりますのでご注意ください。
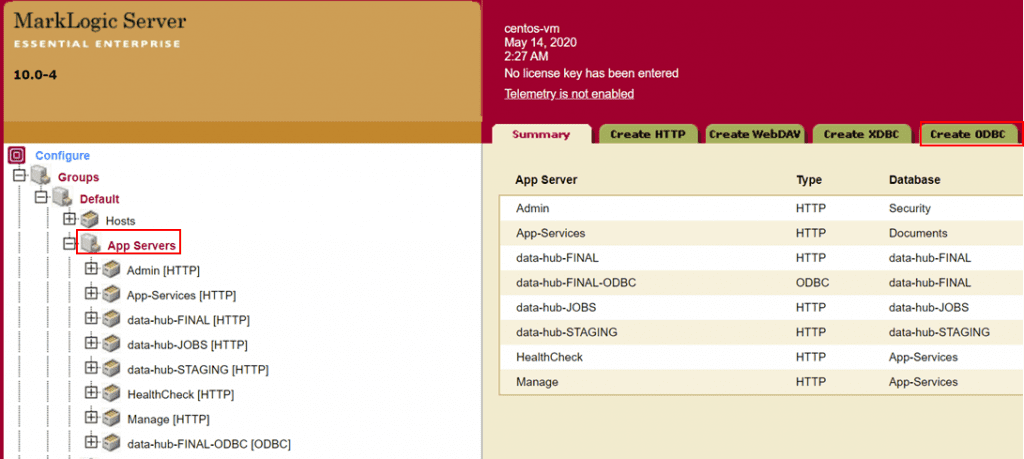
3. ODBCサーバの設定
外部ツールなどからTDE経由でアクセスするためには、MarkLogic上にODBCサーバを作成する必要があります。ODBCサーバはTDEでアクセスするデータベース毎に1つ必要です。 以下は、data-hub-FINALデータベース用にポート番号8014番のODBCサーバを立てた例となります。
ツリー上のAppServersをクリック -> Create ODBCタブをクリック
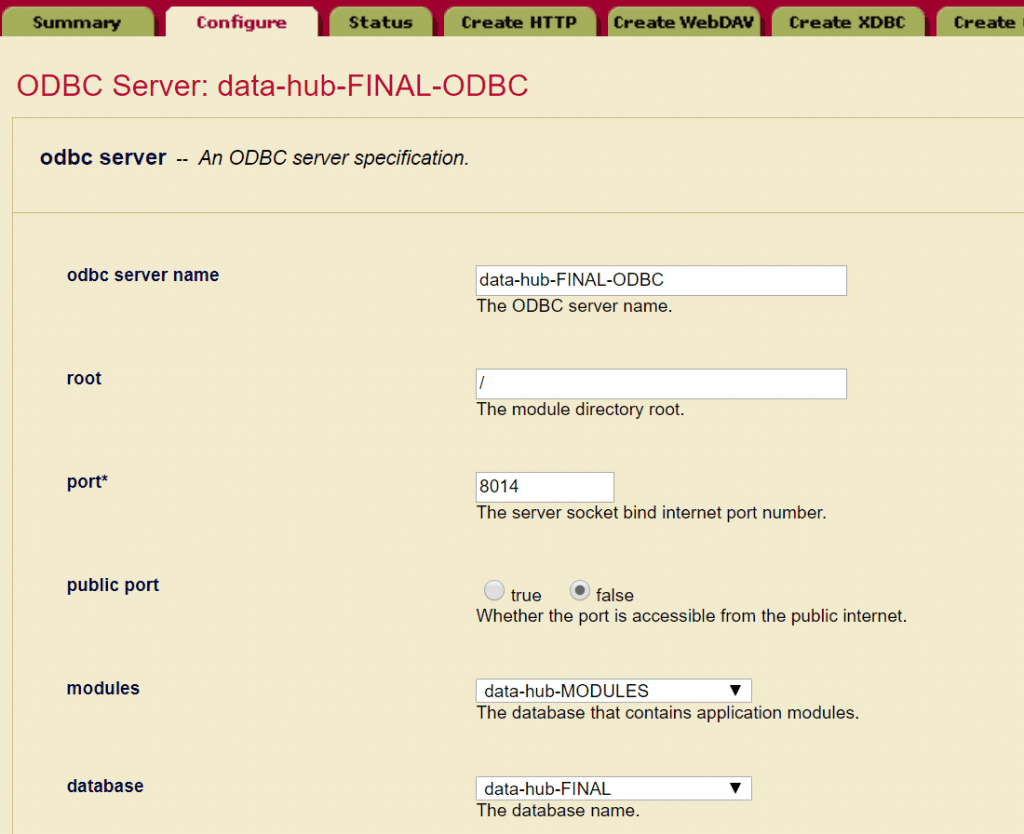
ODBCサーバの設定例
ここで設定したデータベースが、本ODBCサーバに割り当てられるデータベースとなります。 以下以外の設定内容はデフォルトです。
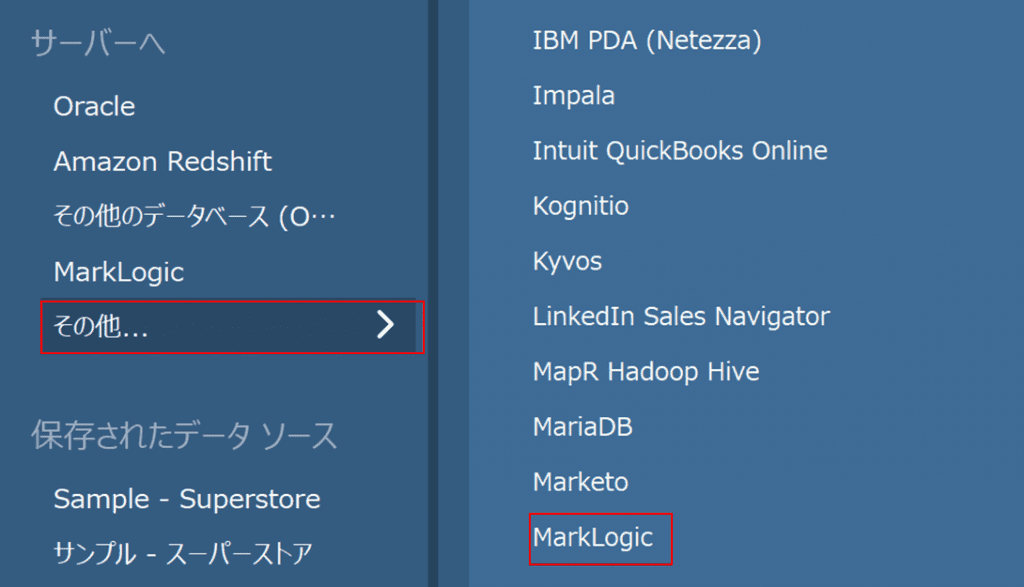
4.Tableauの設定
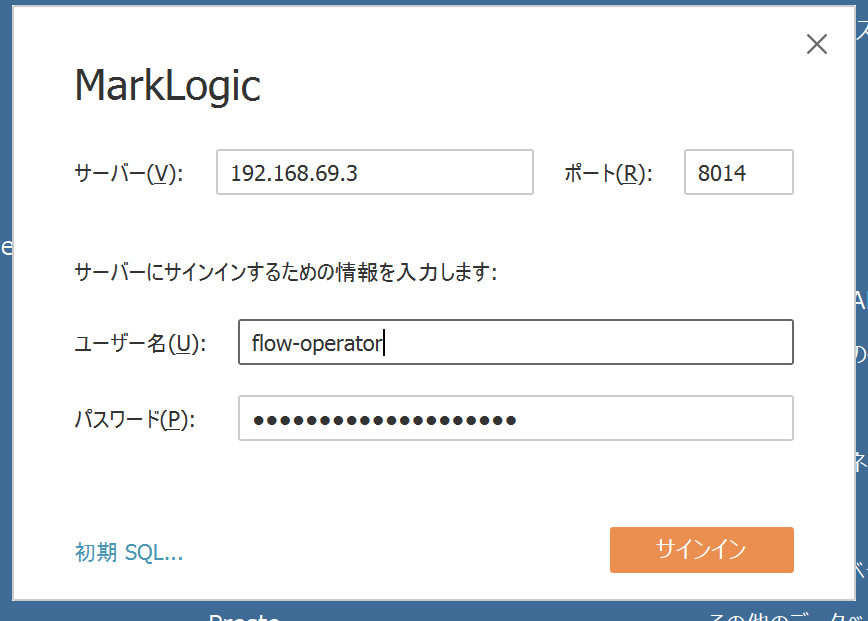
Tableau上では、先ほど設定したMarkLogicのODBCサーバへの接続設定を実施します。 Tableauを起動し、「サーバーへ」内の「その他」、「MarkLogic」を選択します。 ウインドウが出てきますので、接続先ODBCサーバのホスト名(またはIPアドレス)と、先ほどODBCサーバの設定で決めたポート番号、MarkLogicのユーザ名/パスワードを指定してサインインをクリックします。
ここで利用するユーザには、flow-operator(読み込みのみ)またはflow-developer(更新も可能)のロールが付与されている必要があります。Adminロールだけでは不十分となりますのでご注意ください。
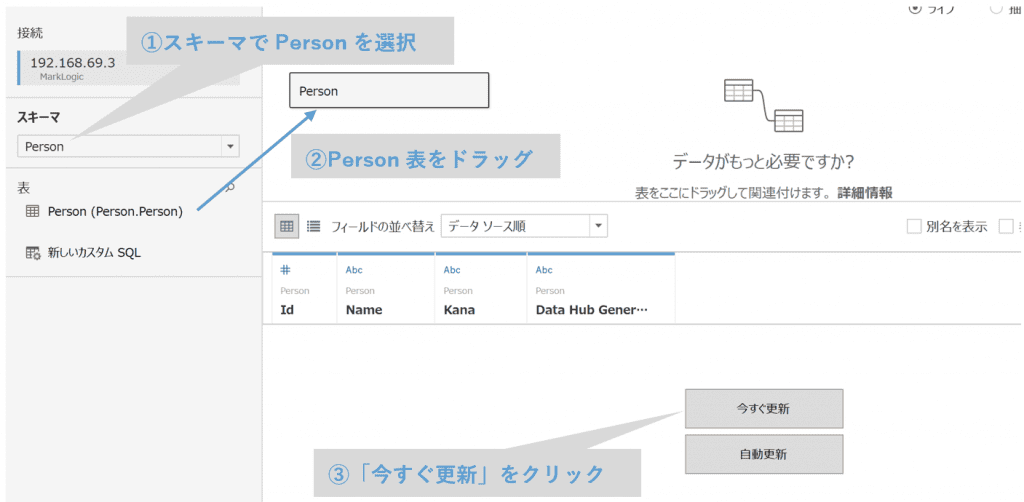
5.Tableau上でのデータ表示
サインインに成功するとこの画面が表示されます。以下の手順に従い、最終的に「今すぐ更新」をクリックすることで、MarkLogic内のでデータがTabelau上に表示されます。
TDEの注意点
データに対してTDEテンプレートが作成されるとTDEアクセス用のインデックスが別途作成されます。インデックスはストレージに保持されます。 TDEに利用されるインデックスはトリプルインデックスとなり、他のインデックスと比較してインデックスサイズが大きくなる傾向がありますので、エンティティの数を増やす、エンティティ内のプロパティを増やす、データの件数を増やす、などの変更に伴いストレージの残容量に注意してください。
まとめ
エンティティはMarkLogicにおける非常に重要な要素です。適切に設計されたエンティティをMarkLogic上に定義することで、データのガバナンスを効かせたり、開発効率を向上させることが可能です。 既存のデータに対して後からエンティティを作成するのは面倒ですが、最初に空のエンティティを作っておいて後からプロパティを追加していくという形にすれば、簡単にエンティティを活用する土台を形成することができます。 エンティティは今後もMarkLogicにおける利用の前提となる機能ですので是非ともご利用ください。
古川拓也
Oracle Databaseのコンサルタンタントを最初のキャリアとして、
KVS、Java、Digital Marketingなど様々なテクノロジーのコンサルティングを経験。
一瞬ビジネスコンサルティングよりになりかけたが、
MarkLogicの技術的な完成度や哲学に心酔しMarkLogicに入社。
MarkLogicを正しく効果的に使って頂けるように、
ベストプラクティスを広く浸透させることをミッションとしている。


