
最近、世界最大規模のヘルスケアシステムに携わっているアーキテクトたちと話す機会がありました。彼らは、大量の医療レジストリ(ヘルスケアデータ)のサイロを統合するために、全データを1000億件以上のセマンティックトリプルに変換したいと考えていました。 このブログでは、これに対して私たちが何を提案したのかをご紹介していきます。
私がこのプロジェクトに参加した際、顧客組織のアーキテクトたちは多数のサイロに散在するペタバイト規模のデータをセマンティックトリプルで関連付けることを決めていました。この方向性自体はいいのですが、具体的なやり方が問題でした。彼らのシステムに5億件のレコードがあり、各レコードに200個の要素がある場合、単純計算でトリプルが1000億個できます。こうして得られたデータセットはガバナンス管理が非常に困難で(人間が読んで理解できたはずのレコードがバラバラにされてしまう)、パフォーマンスも良くなく、また実装にかなりの時間がかかります。
MarkLogicチームは統合要件を理解したうえで、代替案として ドキュメントとセマンティックを組み合わせたモデルによるアーキテクチャを提案しました。このような「マルチモデルアーキテクチャ」であれば、データベース内のオブジェクト数が大幅に削減されます。具体的に言うと、ドキュメントは5億件程度に抑えることができ、おそらくは同数程度のトリプルでこれらを関連付けられます。この複合アーキテクチャの方がパフォーマンスは圧倒的に優れていて、拡張性もあります。また完成までの時間も短く、ガバナンスも良いです。それでは、私たちの提案を詳細に見ていきましょう。
最初の状況
他のほとんどのヘルスケア組織と同様に、この企業にも部分的に重複するデータサイロが数十個(下手すると数百個)ありました。また他の企業と同様に、トランザクション処理やデータウェアハウスにおいてリレーショナル技術に強く依存していました。リレーショナルデータベースは、過去35年におけるオペレーショナル(業務用)のトランザクショナルデータベースの主流となっています。その主な特徴としては、トランザクションの整合性、小さなトランザクションにおける高いパフォーマンス、信頼性があります。一方、多次元データウェアハウスの人気が出ましたが、これは注意深く設定された複数次元において大量データに分析的クエリを実行できるためです。また近年は、グラフデータベースやドキュメントデータベースの人気も出てきています。グラフデータベースは関係性の表現や計算が容易で、ドキュメントデータベースは現実世界を自然に表現したエンティティを扱えるためです。
リレーショナルデータベースには、詳細なモデリングが事前に必要だという大きな問題があります。つまり予め「必要なデータは何か」「相互にどう関係しているのか」「解決したい問題は何か」などについて想定しておく必要があります。
このため「世の中は急激に変化しているのに、アプリケーション固有のデータサイロを作ってしまう」という誤りを犯すことになってしまいます。以下の図1のように、ETLおよびアプリケーション固有のデータセットのせいで、構造化データセット用のデータサイロが大量発生してしまうのです。実際のところ、新規データウェアハウス案件のコストの60%はETLに費やされています。また、リレーショナルデータのサイロ構築には年間360億ドルが使われています。一方、すべての非構造化データを格納するためのサイロも、別途存在します。こういったデータセットをすべて対象とした場合、データソースの個数(場所)は数千になることは容易に想像できます。
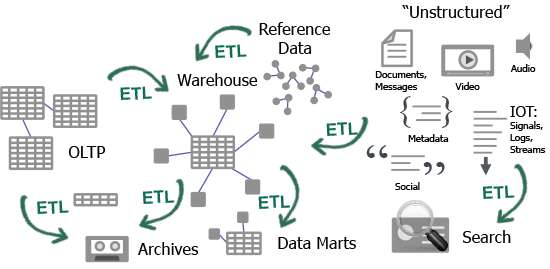
図1:ETLとデータサイロの増殖
この問題を別の観点から見てみましょう。企業は本当はビジネスデータの全体像を求めているのに、実際には業務部門ごとあるいはテクノロジーごとのサイロが発生しているのです(図2)。またこれらを同期させるために大量のETLが必要なのです。
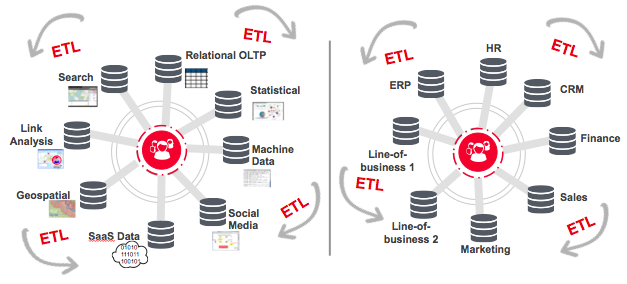
図2:ビジネスサイロやテクノロジーサイロの同期にはかなりの労力が必要
ここで必要となるのは、すべてのデータをスキーマに依存せずに管理でき、意味のあるビジネスコンセプトであらゆるデータを関連付け、信頼性かつ整合性のある方法でデータを格納できる場所です。この場所では、ETL処理(抽出/変換/ロード)を再度やり直さなくても、「ビジネスの遂行(run the business)」と「ビジネスの観察(observe the business)」ができる必要があります。別の言い方をすると、どんどん大きくなるデータを将来にわたってずっと置いておける場所が必要なのです。これがなければ、サイロ間で何度もデータの引っ越しをしているだけで会社のリソースを全部使い切ってしまいかねません。ここで求められているのは「オペレーショナルデータハブ(ODH)」と呼ばれるものです。
オペレーショナルデータハブの主な特徴
アーキテクトなら誰でもハブに強い関心がありますが、実際に使ってみたらがっかりしたということもよくあります。というのも、優良かつ効果的なオペレーショナルデータハブとは以下のようなものなのですが、実際のソリューションのなかにはこれらを実現できていないものがあるからです。
- 統合:オペレーショナル(業務用)&分析用:データとユーザー間の双方向のやり取りを実現
- コンテキスト:セマンティックメタデータによるデータのハーモナイズ
- データセントリック:データレベルで統合。機能レイヤーだけでなく
- 費用対効果:ETL/データコピー/業務サイロ/技術サイロの最小化。ヒト中心の統合
- 安全:リッチなデータガバナンス用のプラットフォーム
- 補完的:既存のアセットやパターンを活用
ODHに関する3つのアプローチ
データサイロ削減用にリレーショナル技術でODHを構築する際の課題については、すでに述べました。このため、リレーショナル以外のものを検討したいと思います。この際、上記のような特徴を念頭に置きながら、以下の異なる3つのアーキテクチャをODHとして使用する際の長所と短所を確認していきます。
- セマンティックトリプルストア/グラフのみのアーキテクチャ
- ドキュメントストアのみのアーキテクチャ
- ドキュメントストアとトリプルストアを組み合わせたマルチモデル
1.セマンティックRDFトリプルストア/グラフのみのアプローチ
リンクトデータ格納用のデータベースは2種類あります。RDFトリプルストアとグラフデータベースで、これらは若干異なります。私の同僚のマット・アレンがこのスレッドで書いているように、グラフデータベースとRDFトリプルストアは、データ(「リンクトデータ」)の関係性にフォーカスしています。データポイントは「ノード」と呼ばれ、データポイント間の関係性は「エッジ」と呼ばれます。ノードとエッジの集まりは網のようであり、興味深い形で視覚化できます。これがグラフデータベースの特徴です。
オペレーショナルデータハブを「トリプルストアのみ」で設計した場合、分断されたデータサイロを柔軟に関係付けられます。この際の主要なメリットと課題については、以下に要約してあります。グラフはあらゆる関係性をモデリングできるので、セマンティックトリプルの整理やクエリを限りなく柔軟に行うことができます。ランタイム時でも、新しいデータタイプや関係性を追加できます。また明確に定義された標準クエリ言語「SPARQL」で、セマンティックトリプルにクエリを実行できます。しかしすべてのオントロジーやコンテンツをセマンティックトリプルでモデリングすることには、課題もあります。オントロジーのセマンティックなコンセプトをトリプルとしてモデリングするのは妥当です(情報の粒度が自然なため)が、この粒度でコンテンツを管理しようとすると課題が発生します。
具体的に言うと、モデリングのレベルが細かすぎます(要素対要素)。これに加えて、元ドキュメントの整合性が保持されません(リレーショナルデータベースの正規化による「シュレディング」に似ています)。このためデータガバナンス(ソースの出自、ドキュメント更新履歴、バイテンポラル情報、セキュリティや権限管理、ドキュメントの削除など)が極めて困難です。ヘルスケアの例でトリプルストアのみを使用した場合、特定の患者コホート(グループ)にクエリを実行した場合、各患者のコンテンツは数百(あるいは数千)個のトリプルとして返されます。また1人の患者の全体像を知ろうとした場合、これらのトリプルすべてをジョインする必要があります。そのうえ、このプロセスをコホート内の各患者ごとに繰り返す必要があります。つまりジョインが数百万回から数十億回も必要となるため、これがボトルネックとなり、研究者の不満が募ることになってしまいます。
グラフ/RDFトリプルストアのみのアプローチの長所
- 無限の柔軟性 – あらゆる構造をモデリング
- ランタイム時に型と関係性を定義可能
- エンティティをあらゆるものと何らかの方法で関係付けられる
- 関係性のパターンをクエリ
- 標準的なクエリ言語(SPARQL)の使用
- データに関して最大限のコンテキストを作成
グラフ/RDFトリプルストアのみのアプローチの短所
- 詳細すぎるためモデル化が困難
- 他のシステムとの統合が困難
- 標準的でないクエリ言語。人材が極めて少ない
- ドキュメントをジョインしたり、類似しているが分散しているコンテンツを処理するための効果的な方法が必要
2.ドキュメントのみのアプローチ
ドキュメントデータベースはスキーマに依存しないため、データを「そのまま」読み込み、求められる出力に合わせてアジャイルな「ジャストインタイム」方式でモデリングできます。このため最短時間で生産性を上げられます。データを理想的な形に正規化する必要があるリレーショナルと違って、さらに多くの種類のサービスや分析に対応できます。
作業は標準的なETL(抽出/変換/ロード)順ではなく、ELT(抽出/ロード/変換)順となります。ドキュメントを使うことで、読み込んだままの形で、あるいは自然に利用できる形でデータセットを永続化できます。ここでのデータモデリングの目標は、アプリケーションまたは企業全体のビジネスに関するオブジェクトを特定し、それらのオブジェクトに自然に適合するようにドキュメントをモデリングすることです。 これにより、技術的知識がないユーザーでも読みやすく理解しやすい、人間指向の直感的なモデルを構築できます。
たとえば、ヘルスケアモデルの外来診療ドキュメントでは、ルート要素によりこのドキュメントが「外来診療」に関するものであること、またこの診療情報には患者、診断、治療計画、病院名、治療方法が含まれることを簡単に確認できます。これに加えて、ドキュメントの元のコンテキストおよび整合性が保持されるため、データガバナンスの問題(ソース/ソフトウェアのリネージ、ドキュメント更新履歴、バイテンポラル情報、セキュリティ、権利管理、ドキュメント削除処理など)を極めて簡単に管理できます。しかし、自然な形式のままのドキュメントを使う場合、他のデータあるいは「名前が違うが中身は同じデータソース」と関係づけたりジョインするといったいくつかの重要な課題を解決しなければなりません。
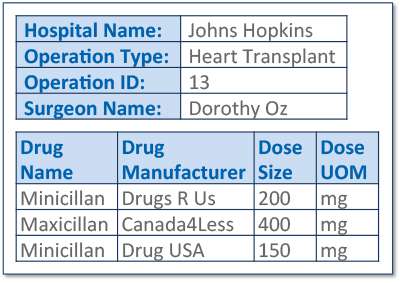
ドキュメントのみのアプローチの長所
- 妥協せずに業務を正確にモデル化
- 短期間での開発
- スキーマレス、ランタイム設計、リッチ、JSON/XML/RDFデータ構造
- あらゆるものをコンテキスト内でクエリ
- データを意味のある情報に変換
- 重要度に関してクエリできる
ドキュメントのみのアプローチの短所
- 予期できないデータ構造用の防御的プログラミング
- プラットフォームにお金がかかる
- ツールが成熟していない
- 人材がいない
3.セマンティック+ドキュメントのマルチモデルアプローチ
ドキュメントストアおよびトリプルストアでODHを設計する「マルチモデル」アプローチでは、「人間が理解できる自然なビジネスオブジェクトモデル」と、「モデル間の関係性を人間が理解できるセマンティック」の両方の長所が実現されます。データガバナンスがシンプルであり、ドキュメント間のジョインを直感的かつ短時間で行えます。
MarkLogicのようなデータプラットフォームによりドキュメントとセマンティクスを結び付けることで、データサイロを素早く統合できます。また、このODH上でジャストインタイムにアプリケーションを開発できます。 MarkLogicのアプローチは、同様の課題におけるリレーショナルデータベースのアプローチよりもはるかに柔軟であり、市場投入時間を大幅に短縮できることが証明されています。
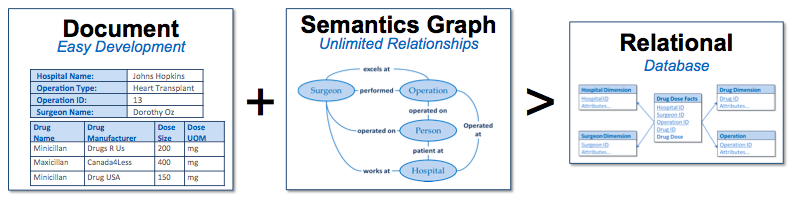
ドキュメント+トリプルストアはリレーショナルのみのものよりも柔軟
セマンティック+ドキュメントのマルチモデルアプローチの長所
- 「そのまま」のデータにより、データガバナンス(リネージ、履歴、ライフサイクル、セキュリティ)が強化されます。
- オントロジーを使うことで、トリプルでドキュメントにタグ付けしたりエンリッチしたりできます。
- 一元化されたクエリビューでオントロジーを使うことで、多様なソースから類似コンテンツを探せます。
- 柔軟なAPIにより、SPARQL、REST、Java、JavaScriptによる検索ができます。
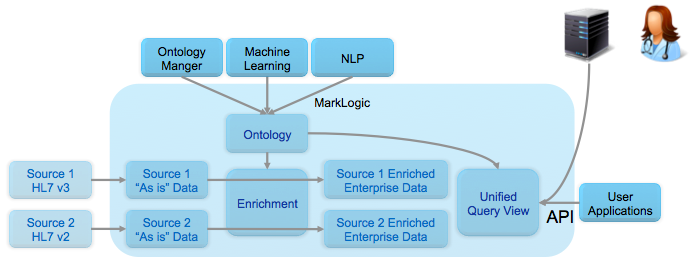
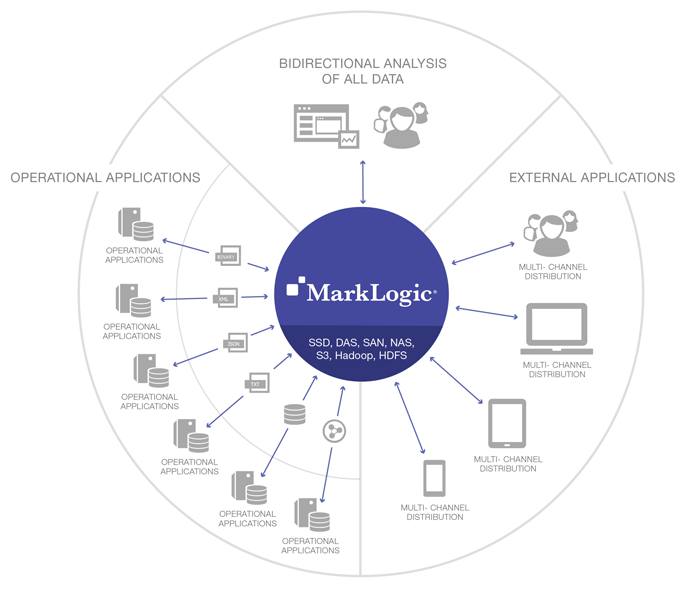
上の図は、マルチモデル(セマンティック&ドキュメント)アーキテクチャをMarkLogicプラットフォームに実装して、ODHを作成する方法を示しています。 APIまたはエンドユーザー固有アプリケーションのアクセス対象である各ソースでは、ビジネスオブジェクト(患者、病院、治療など)のフォーマット化、格納、提供形式の標準がそれぞれ異なっている可能性があり、これらを集約する必要もあります。MarkLogicの柔軟なデータモデルでは、これらのオブジェクトをドキュメントの形で「そのまま」取り込んで格納できます。オントロジーマネージャやその他の手法(機械学習や自然言語処理など)を使用すれば、意味が似ているフィールドをマッピングしてまとめ、ビジネスオブジェクト間の関係性用のオントロジーを作成および管理できます。MarkLogicにはエンタープライズトリプルストアが標準装備されているため、このようなオントロジーを直接格納できます。データの読み込み時に、オントロジーによって定義されたセマンティックマッピングによってデータをエンリッチできます。この統合されたクエリビューでは、オントロジーによってデータ提供時にもセマンティッククエリの機能を利用できます(SPARQLや検索でクエリを拡張できます)。あらゆるレジストリからのコンテンツを組み合わせたものを、REST APIを通じて他のシステムやアプリケーションに提供できます。
下の図は、データ形式が異なる複数のレジストリの「患者ID」のような類似コンセプトをセマンティックでクエリしたり、ハーモナイズ/正規化する方法を示しています。ヘルスケア業界においては、HL7 v3、HL7 v2、FHIRといった各種データ標準ごとに「患者ID」の表現方法が違います。セマンティックトリプルを使うことで、これらの標準のうちどれが社内の「患者ID」で使用されているのかを示すことができます。

私たちからの提案に興味を持ったこのチームは、このマルチモデル(ドキュメント&セマンティック)のアーキテクチャを採用しました。その後の展開についてはまた別途寄稿します。

イムラン・チョードリ
イムランは、大規模で多様なデータ統合と分析を管理するエンタープライズ仕様のNoSQLソリューションをヘルスケアIT市場に提供することに専念すべく、MarkLogicに入社しました。臨床データのオーバーロード問題を解決するためにApixioを共同設立し、HIPAA準拠の臨床ビッグデータ分析プラットフォームを開発してきました。このビッグデータプラットフォームは、Hadoop、Cassandra、SolrなどのクラウドコンピューティングベースのNoSQL技術を多用しています。それ以前は、Anka Systemsを共同設立し、EyeRouteのビジネス開発、製品定義、エンジニアリング、およびオペレーションに注力してきました。EyeRouteは、世界初の分散型ビッグデータ眼科画像管理システムです。イムランは、IHE EyeCare Technical Committeeの共同議長も務めました。Anka Systems以前は、オペレーショナルパフォーマンスに基づく世界初のメタコンテンツ配信ネットワークであるFastTideを設立し、CTOを務めていました。マギル大学で電気工学の学士号を、コーネル大学で同分野の修士号を取得しており、業界で25年以上の経験があります。


