
企業がMDM(マスターデータ管理)を検討しはじめる要因は、たくさんあります。通常、各業務部門には以下のような課題があることでしょう(それぞれの重要性は各部門のニーズによって異なります)。
- 収益増加(CRMの効果向上)
- コスト削減(プロセスの効率化)
- 規制順守
- 意思決定の改善
- アジャイル性の改善
しかし技術的な課題(部分的にはレガシー技術のせい)によって、こういったビジネス目標は達成できないことがあります。初期のDXプロジェクトの多くは、ビジネスイノベーション/トランスフォーメーションで求められるMDMシステムの機能を全くあるいは部分的にしか提供できませんでした。提供できなかった機能として以下のものがあります。
- 既存のデータセットをMDMモデルに適合させる
- データモデル(ゴールデンレコード)を進化させるためのアジリティ
- 散在する大量のデータをマスタリング(重複解消)するための効率的な処理
- 毎日大量のレコード(数百万件)を処理。リアルタイム/ストリーミングも
- 進化する複雑なモデルにおけるリファレンスデータの処理
- 大規模拡張時におけるデータ監査、リネージ、出自
- MDMデータの業務活用、セキュアなデータアクセス、スピードを落とさずに企業規模に拡大可能
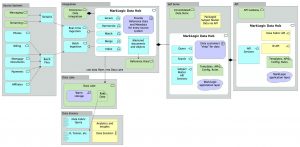
通常、リレーショナルに基づくMDMでは、プロジェクトの初期段階で対象データソースのモデリングを行い、その後すべての入力データソースを適合すべきデータモデルを1つ作成します。しかしデータを変換してこの標準的データモデルに準拠させるには、大量のETLが必要です。また、この作業に時間がかかっている間に、世の中の状況もメインシステムのデータスキーマも当然のことながら変わっていきます。そしてこれらの変更のたびに、その分析と対応作業が必要となります。
通常、共通データ項目の格納方法は複数存在します。この結果、散在する同一ビジネスエンティティに関するレコードをまとめようとした場合、どのレコードの信頼性が最も高い/正確なのかについての判断が困難です。
またグローバリゼーションによって、データ管理がさらに困難かつ複雑になるという問題もいろいろと発生しています。例えば、複数の言語/文字セットの問題、またグローバルでの業務展開によりデータを24時間体制で提供しなければならないという課題があります。
このようにプロジェクトが非常に複雑なため、「あらゆるシステムと他のプラットフォームとのやり取り」「データのミスマッチ」「業務部門からのニーズが変わり続ける」などに対処するにはまず何をすべきかが分かりづらいです。
MarkLogicは、お客様のこういった問題を長年にわたって解決してきています。MarkLogicのプラットフォームを使うと、MDMの重要要件を満たしながらも、複雑なデータ(コンプレックスデータ)から価値を引き出すことができます。
それでは、こういったプラットフォームの成功には何が必要なのでしょうか。それは「小さく始めて(スモールスタート)、アジャイルを維持し、価値を生み出し、反復する」ということです。
MarkLogicを選ぶ理由
- アジリティが成功への鍵
- データはどんどん複雑になり、量が増え、形が変わり続けます。またデータ間の関係性もこれまで以上に重要になってきています。
- データ間の関係性を格納する(ソースの選定、データの変換、データ間の関係性の設定など)うえで最も柔軟なのは、セマンティックを利用した方法です。
- トリプルを使うことで、データ間の関係性を驚くほど強力かつ柔軟に記述できます。
- MarkLogicは、長年にわたって民間企業や政府機関において複雑なナレッジグラフの作成やインデックス付けを行ってきています。
- データは常に変わり続けていますし、また新しいデータの登場によりファクト(「事実」)は変わっていきます。一般的なMDMソリューションでは、出自に基づくデータへの新しい処理が極めて困難です。
- MarkLogicには、出自トラッキングのフル機能が備わっており、データの何らかの変化の把握や、いったんまとめたデータを切り離すこと(アンマージ)も必要に応じて実行できます。
- またMarkLogicによるデータ管理では「何も捨てない」こともできます。データレコード全体およびその出自やアクションを、必要に応じて保持できるのです。
- リレーショナルデータベースではモデルを事前定義する(つまり適切な列や表を作成しておく)必要があるため、事前のモデリングが大量に必要になるばかりか、変化への対応が困難です。
- MarkLogicはドキュメントベースのマルチモデルであり、データの読み込み/管理/他のシステムへの提供が柔軟に行えます。
- 拡大する重要なデータのほとんどは、非構造化データ(メール、チャット履歴、帳票など)です。
- MarkLogicは、毎日数百テラバイトの非構造化データを読み込み、インデックスを付け、分類し、検索可能にできます。
- アクセスできなければデータには何の意味もありません。しかし既存のMDMシステムの多くは、アクセスを犠牲にしてデータに注力しています。
- MarkLogicは、その技術の中核に検索エンジンがあり、インデックスを付け、分類し、適切なデータを適切なタイミングで提供できます。
- また業界でもトップクラスのセキュリティ制御により、適切な人だけが適切なタイミングでデータを見られるようにできます。
- 扱っているエンティティの360ビュー(全体像)を本当に実現するには、リファレンスデータ(統制語彙/タクソノミー、第三者提供データなど)を含める必要があります。
- MarkLogicにはRDFデータの読み込み・管理機能があるので、リファレンスデータの読み込み、管理、関連付けが容易です。
質問がある方は、ぜひCSM-MarkLogic@progress.comにご連絡ください。

ジェームズ・ケンウッド
ジェームズ・ケンウッドはEMEAカスタマーサクセスマネージャです。ヨーロッパ内外の多くの既存顧客の継続的な成功を実現する責任を負っています。MarkLogicのお客さまであるピアソンでエンジニアリングディレクターとして働いていましたが、2019年にMarkLogicに入社しました。この経験から得た、顧客としてのユニークな視点と、顧客がベンダーに求めていることへの理解によって、その実現に貢献しています。


